In 2026, a complete self-hosted infrastructure stack runs 82 containers on a single server with zero cloud bills, achieving 99.9% uptime and automated CI/CD. Key tools include Proxmox VE, Traefik, Cloudflare Tunnels, Prometheus, Grafana, and AI inference on an NVIDIA GTX 1650. This approach cuts $2,530 monthly cloud expenses to just $30 in electricity, proving a viable alternative for teams with Linux expertise and steady workloads. Next steps: start small, secure with zero-trust, and monitor thoroughly to scale confidently.
Dev & Open Source
82-Container Self-Hosting Slashes Cloud Costs

Sources (1)
More from Dev & Open Source
-
AI Revolutionizes ETL Pipeline Development

Despite advances in platforms like Databricks and Snowflake, ETL pipeline creation remains a slow, error-prone bottleneck in data engineering. The new Candor Data Platform introduces an AI-driven, prompt-based approach that generates production-ready pipeline code automatically, cutting down manual coding and cross-database complexity. This innovation promises to accelerate data workflows dramatically, allowing teams to focus on business logic rather than plumbing. As data volumes and system diversity grow, such AI-powered tools could redefine how pipelines are built and maintained.
-
Why Build a Local Terminal Workspace?
Developer algebrain created a local terminal workspace to mimic a desktop app experience, addressing frustrations with tmux's remote-focused design. Unlike tmux, which excels at managing remote sessions and persistent processes, this new tool prioritizes local workflows with features like tabbed layouts, session restoration, and native clipboard support. The motivation was to avoid complex configurations and plugins, favoring simplicity and predictability. This project highlights a shift toward tailored local tools, inviting others to share their terminal setups.
-
Subqueries vs CTEs: SQL Showdown

Subqueries and CTEs are essential SQL tools for data analysts, but they serve different purposes. Subqueries offer quick, simple filtering inside queries, ideal for straightforward tasks, while CTEs provide a clearer, step-by-step structure that improves readability and debugging for complex logic. As datasets grow and queries get complicated, switching to CTEs can make your SQL code more maintainable and efficient. Understanding when to use each method is key to mastering SQL in real-world data analysis.
-
Cache-Aside's Hidden Database Drain
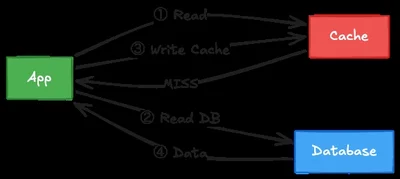
A subtle bug in the Cache-Aside pattern causes databases to be hammered with redundant queries when cached data is legitimately empty, returning None. This silent issue arises because None is used both to signal a cache miss and to represent an empty result, leading to repeated database hits and performance degradation. The fix involves using a Null Sentinel—a unique marker to distinguish between 'no cache entry' and 'cached empty result.' This pattern is crucial for robust caching and avoiding hidden load spikes in production systems.
-
Automate Monday.com Task Fixes with AI

Monday.com users often face the hassle of manually correcting AI-generated task descriptions that end up misplaced in updates rather than the description field. Developer insights reveal the root cause: a missing API tool for setting item descriptions, forcing agents to misuse the 'create_update' function. By building a custom skill that correctly sequences API calls, this workaround automates proper task creation, eliminating tedious manual fixes. The next step is a proposed upstream API change to simplify this process, promising smoother AI integration for all users.
-
Mastering Company Knowledge Bases

Building a company knowledge base often starts organized but quickly devolves into chaos. The key to maintaining order lies in three pillars: structuring content by organizational chart rather than projects, enforcing strict access controls, and implementing powerful search features including tagging and cross-linking. Regular quarterly audits ensure the system stays efficient and secure. Companies should choose platforms like Confluence or Notion based on team size and needs to keep knowledge accessible yet protected.
-
Building Interfaces That Fail Gracefully
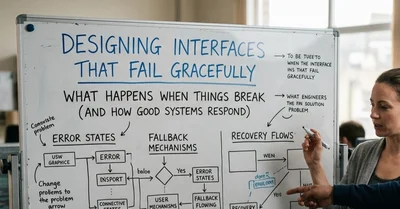
When users interact with web apps, things often go wrong—slow connections, server errors, or blocked requests. Lee Mee highlights how designing for failure, not just success, is crucial. By locking UI states, handling asynchronous errors with robust fetch wrappers, and providing fallback options like direct email contacts, apps stay user-friendly even in chaos. This approach builds trust and prevents frustration, proving that true quality lies in graceful failure handling.
-
Kimi K2.6 Pushes Limits of AI Orchestration

Moonshot AI's new model, Kimi K2.6, is breaking ground by running AI agents continuously for days, handling complex tasks like system monitoring and incident response autonomously. This exposes critical flaws in existing enterprise orchestration frameworks, which were designed for short-lived agents and struggle with maintaining state over long periods. As AI capabilities outpace orchestration tools, companies face urgent challenges in governance and infrastructure adaptation. The future will demand new architectures and stronger oversight to safely harness these powerful long-running agents.
-
Master Git History: Undo with Confidence

Git users often face the challenge of undoing changes or rewriting history without losing work. The recent guide from Towards Data Science breaks down how Git records changes through the working directory, staging area, and repository commits. It highlights powerful commands like
git reset --soft HEAD~1to safely undo commits while preserving staged changes. This knowledge is crucial for developers collaborating on complex projects to maintain clean, accurate Git histories. Expect more tutorials and live talks to deepen understanding of Git's internal mechanics.