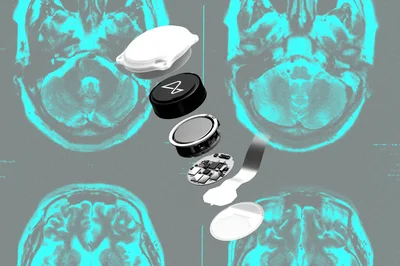
Исследование Конгчи Иня и соавторов показало, что с помощью предсказательного кодирования мозга можно восстанавливать язык по данным fMRI, используя способность мозга прогнозировать будущие слова. Это открытие углубляет понимание нейронных механизмов семантической обработки и обещает прорыв в технологиях интерфейсов мозг-компьютер. Впереди — адаптация моделей для практического применения в реальном времени.
AI • Машинное обучение
Предсказательное кодирование мозга восстанавливает речь
Источники (3)
More from AI • Машинное обучение
-
Тестирование ИИ-агентов в медадминистрировании
 исследовать →
исследовать →Представлен новый бенчмарк HealthAdminBench для оценки ИИ-агентов в задачах медицинского администрирования, где ежегодные расходы превышают 1 трлн долларов. Включены реалистичные графические интерфейсы и 135 экспертных задач по направлениям: предварительное одобрение, апелляции и обработка заказов на медицинское оборудование. Несмотря на высокие показатели по отдельным подзадачам, лучший агент достиг лишь 36,3% успешности в полном выполнении задач, что указывает на сложности с надежностью. Это важный шаг для развития ИИ в сфере медадминистрирования.
-
ИИ-агенты меняют поиск лекарств
 исследовать →
исследовать →ИИ-агенты демонстрируют способность самостоятельно анализировать и восстанавливать сложные программы, что значительно ускоряет разработку новых лекарств. Проект MirrorCode показал, что ИИ может переписывать тысячи строк кода без доступа к исходникам, что свидетельствует о стремительном прогрессе технологий. Это открывает новые горизонты для фармацевтики и биотехнологий, при этом особое внимание уделяется безопасности и этике. Эксперты отмечают, что ИИ уже меняет подходы к поиску и созданию лекарств.
-
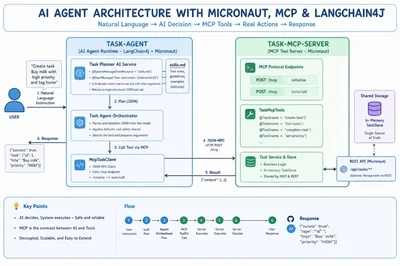
Создание рабочих AI-агентов на LangChain4j
 исследовать →
исследовать →Разработчики всё активнее создают AI-агентов, способных не только понимать язык, но и самостоятельно выполнять задачи. С помощью LangChain4j, Micronaut и протокола Model Context Protocol (MCP) можно построить Java-агентов, которые интерпретируют команды, принимают решения и выполняют действия без сбоев. Эта технология решает проблему надёжного взаимодействия языковых моделей с инструментами без облачных сервисов. Впереди — широкое внедрение MCP для автоматизации в разных сферах.
-
Vision AI на iPhone — полностью офлайн
 исследовать →
исследовать →Нейронный движок iPhone способен выполнять 35 триллионов операций в секунду, и теперь на его базе работает приложение Off Grid, позволяющее запускать модели Vision AI без подключения к интернету и без регистрации. Это значит, что обработка изображений и ответы на вопросы по фото происходят прямо на устройстве, без передачи данных на серверы. Такой подход обеспечивает максимальную приватность и удобство. В дальнейшем можно ожидать появления новых приложений с офлайн-искусственным интеллектом.
-
Agent² RL-Bench меняет правила обучения RL
 исследовать →
исследовать →Новый бенчмарк Agent² RL-Bench ставит перед агентами задачи с нелинейными цепочками действий, требующими сложного планирования и навигации. В отличие от прежних тестов, здесь используются направленные ацикличные графы, что значительно усложняет выполнение заданий. Лучшие модели достигают лишь 37,2% точности, что подчёркивает необходимость развития методов обучения с подкреплением. Этот инструмент открывает новые возможности для исследований и совершенствования RL-агентов.
-
LLM нуждаются в механизмах эмпатии
исследовать →
В апреле 2026 года исследователи представили работу, в которой подчёркивается, что современные большие языковые модели (LLM) систематически не справляются с задачей эмпатии, искажают эмоциональные и контекстуальные нюансы. Выделены четыре основных механизма сбоев — ослабление чувств, несоответствие детализации, избегание конфликтов и лингвистическое дистанцирование, что снижает качество взаимодействия с человеком. Авторы призывают внедрять в обучение LLM специальные методы, учитывающие эмпатию, чтобы повысить их надёжность в социально значимых сферах. В дальнейшем планируется разработка новых тестов и сигналов обучения, ориентированных на эмпатию.
-
LLM ошибочно вызывают нерелевантные инструменты
 исследовать →
исследовать →Исследование выявило распространённую ошибку в работе больших языковых моделей (LLM) — структурное смещение выравнивания, из-за которого модели вызывают инструменты, не имеющие отношения к запросу пользователя. Новый набор данных SABEval помогает отделить структурное совпадение от смысловой релевантности и показывает, что эта проблема остаётся вне поля зрения существующих оценок. Понимание механизма ошибки позволит улучшить точность и надёжность ИИ, минимизируя ненужные вызовы инструментов. В дальнейшем учёные планируют оптимизировать баланс между семантикой и структурой при принятии решений.
-
PepBenchmark: Новый стандарт ИИ для пептидов
исследовать →
PepBenchmark представлен как первая единая платформа для машинного обучения пептидов, решающая проблему отсутствия стандартизации в разработке лекарств. Включая 35 наборов данных, стандартизированный процесс обработки и рейтинг моделей, проект охватывает ключевые направления пептидной терапии. Это открывает новые возможности для ускорения исследований и внедрения инноваций в фармацевтике.
-
Audio-Omni: единая модель для звука
 исследовать →
исследовать →Появилась Audio-Omni — первая комплексная система, объединяющая генерацию, редактирование и понимание аудио в сферах звука, музыки и речи. Архитектура сочетает замороженную мультимодальную языковую модель и обучаемый диффузионный трансформер, а масштабный датасет AudioEdit с миллионом пар редактирования решает проблему нехватки данных. Эта разработка превосходит специализированные модели и задаёт новый стандарт в аудиоискусственном интеллекте. Впереди — внедрение Audio-Omni в реальные проекты и творческие процессы.
-
Особенности LLM не всегда помогают RL-трейдингу
исследовать →
В новом исследовании показано, что большие языковые модели (LLM) способны создавать предсказуемые признаки для агентов с подкрепляющим обучением (RL) в трейдинге, однако при макроэкономических шоках эти признаки могут ухудшать работу агентов. Используя оптимизацию подсказок, учёные получили значимые корреляции (IC выше 0,15), но в условиях сдвига распределения агент с LLM-признаками уступал базовому варианту, опирающемуся только на цены. Это подчёркивает важность учёта устойчивости политик RL в нестабильных рыночных условиях. В дальнейшем планируется разработка методов повышения надёжности таких систем.
-
CodaRAG: Новый уровень ассоциативного вывода
исследовать →
Новая система CodaRAG, вдохновлённая принципами Комплементарного обучения, кардинально меняет подход к Retrieval-Augmented Generation, объединяя разрозненные данные в логические цепочки. В отличие от традиционных методов, которые рассматривают доказательства по отдельности, CodaRAG активно исследует ассоциативные связи, что позволяет повысить точность поиска на 7-10% и качество генерации на 3-11%. Это открывает новые горизонты для надёжного и глубокого анализа информации в больших языковых моделях. В дальнейшем планируется интеграция CodaRAG с существующими системами и расширение областей применения.
-
Новая система обучения контролю вывода ИИ
исследовать →
Учёные представили инновационный подход, позволяющий даже небольшим языковым моделям с 1 млрд параметров автоматически изучать и применять контекстно-зависимые ограничения при генерации текста. Это устраняет необходимость ручного задания правил и обеспечивает более точный и надёжный контроль над результатом. Такой прорыв открывает новые возможности для повышения качества и безопасности ИИ. В дальнейшем планируется расширить испытания и внедрять технологию в практические задачи.
-
Новый метод выявления утечек данных в LLM без обучения
исследовать →
Дэвид Илич и соавторы представили EZ-MIA — эффективную атаку на языковые модели, не требующую дополнительного обучения. Метод выявляет случаи, когда модель ошибочно повышает вероятность токенов из обучающей выборки, что указывает на запоминание конфиденциальной информации. Это значительно повышает точность обнаружения при низком уровне ложных срабатываний, что важно для практического аудита приватности. В условиях роста применения больших языковых моделей EZ-MIA поднимает тревогу о безопасности данных и стимулирует разработку новых защит.
-
Глубокое обучение меняет принятие решений
 исследовать →
исследовать →В работе И. Эсры Буюктахакина показано, как глубокое обучение дополняет классические методы оптимизации при принятии решений в условиях неопределённости. Это открывает новые возможности для создания масштабных систем, способных работать в сложных и динамичных средах. Такой подход расширяет роль искусственного интеллекта от простого прогнозирования к поддержке реальных решений. Впереди — практическое внедрение и проверка эффективности на больших данных.
-
Улучшение безопасности LLM во время вывода
исследовать →
Исследование, проведённое Панкаяраджем Патманатаном и коллегами, показало, что метод делиберативного выравнивания, направленный на передачу навыков рассуждения от более сильных моделей к меньшим, значительно повышает безопасность больших языковых моделей. Однако между «учителем» и «учеником» сохраняется разрыв в выравнивании, что сказывается на безопасности и полезности моделей. Это подчёркивает важность дальнейших исследований для повышения надёжности ИИ в процессе работы.
-
Скрытые предвзятости омнимодальных ИИ-моделей
 исследовать →
исследовать →Недавнее исследование выявило значительные демографические и языковые предвзятости в омнимодальных языковых моделях, работающих с текстом, изображениями, аудио и видео. В то время как задачи с изображениями и видео показывают относительно равномерные результаты, аудиозадачи демонстрируют существенные различия в точности по возрасту, полу и языку. Эти данные подчеркивают необходимость всесторонней оценки справедливости моделей, поскольку их применение становится всё шире. Эксперты предупреждают, что без устранения таких предвзятостей ИИ рискует закрепить социальное неравенство.
-
CheeseBench: ИИ в задачах нейронауки грызунов
исследовать →
Появился новый бенчмарк CheeseBench, оценивающий крупные языковые модели на девяти классических поведенческих задачах нейронауки, основанных на опыте с грызунами. Лучшая модель Qwen2.5-VL-7B достигла успеха в 52,6% случаев, что значительно выше случайного уровня, но ниже результатов животных — 78,9%. Это важный шаг в изучении когнитивных возможностей ИИ и его приближении к биологическому мышлению. Впереди — улучшение моделей и расширение тестов.
-
ACE-TA: Новый уровень обучения программированию
исследовать →
ACE-TA — агентный помощник для обучения программированию, который самостоятельно отвечает на вопросы, генерирует тесты и проводит пошаговое обучение коду с помощью больших языковых моделей. Эта система объединяет точные ответы, адаптивные задания и интерактивное сопровождение, что значительно улучшает процесс усвоения материала. Внедрение ACE-TA открывает новые возможности для персонализированного и эффективного обучения. Впереди — масштабное применение и проверка в реальных образовательных условиях.
-
Этика ИИ в программировании: что важно знать
 исследовать →
исследовать →ИИ-агенты для написания кода перестали быть экспериментом и уже активно используются в компаниях разных масштабов. Однако этические нормы отстают, вызывая вопросы о праве собственности на код, предвзятости, безопасности и признании авторства. Эти проблемы не гипотетические — они проявляются в виде скрытых ошибок, уязвимостей и споров о заслугах. Разработчикам необходимо выработать чёткие правила, чтобы ответственно использовать ИИ в разработке.