Дослідники розробили унікальну систему, що дає змогу навіть невеликим великим мовним моделям із 1 млрд параметрів автоматично вивчати та застосовувати контекстно-залежні обмеження під час генерації тексту. Це усуває потребу в ручному прописуванні правил і підвищує точність та надійність результатів. Відкриття відкриває нові горизонти для покращення якості та безпеки ШІ. Наступним кроком стане масштабне тестування та впровадження у практичні сфери.
AI • Машинне навчання
Новий підхід навчає ШІ контролювати текст
Джерела (3)
More from AI • Машинне навчання
-
Оцінка ІІ-агентів у медадмініструванні
 дослідити →
дослідити →Представлено новий бенчмарк HealthAdminBench для оцінки ІІ-агентів у завданнях медичного адміністрування, де щорічні витрати перевищують 1 трильйон доларів. Він охоплює реалістичні графічні інтерфейси та 135 експертно визначених завдань у сферах попереднього затвердження, апеляцій та обробки замовлень на медичне обладнання. Незважаючи на високі результати у підзавданнях, найкращий агент досяг лише 36,3% успішності у повному виконанні завдань, що свідчить про проблеми з надійністю. Це важливий крок для розвитку ІІ у медадмініструванні.
-
Штучний інтелект прискорює пошук ліків
 дослідити →
дослідити →Інтелектуальні агенти на основі ШІ тепер можуть самостійно аналізувати та відтворювати складні програмні коди, що значно пришвидшує розробку нових ліків. Технологія MirrorCode демонструє здатність ШІ переписувати тисячі рядків коду без доступу до вихідного тексту, що свідчить про стрімкий розвиток галузі. Це відкриває нові можливості для фармацевтики з урахуванням безпеки та етики. Фахівці прогнозують, що ШІ докорінно змінить процеси пошуку і створення медикаментів.
-
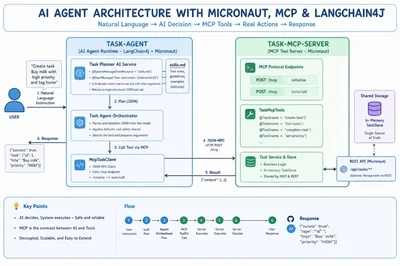
Створення ефективних AI-агентів з LangChain4j
 дослідити →
дослідити →Розробники дедалі частіше створюють AI-агентів, які не лише розуміють мову, а й самостійно виконують завдання. Використовуючи LangChain4j, Micronaut та протокол Model Context Protocol (MCP), можна будувати Java-агенти, що інтерпретують інструкції, приймають рішення й виконують дії без помилок. Цей підхід вирішує проблему надійного зв’язку мовних моделей з інструментами без залежності від хмарних сервісів. Наступний крок — масштабне впровадження MCP для автоматизації в різних галузях.
-
Vision AI на iPhone працює повністю офлайн
 дослідити →
дослідити →Нейронний процесор iPhone тепер дозволяє запускати моделі Vision AI без підключення до інтернету та без облікового запису. Безкоштовний додаток Off Grid дає змогу аналізувати фото, читати документи та отримувати відповіді на основі зображень прямо на пристрої, не передаючи дані на сервери. Це важливий крок для збереження приватності користувачів та зручності використання. В майбутньому очікується поява ще більшої кількості офлайн-додатків із штучним інтелектом.
-
Agent² RL-Bench змінює підхід до навчання RL
 дослідити →
дослідити →Новий бенчмарк Agent² RL-Bench ставить перед агентами завдання з нелінійними ланцюгами дій, що вимагають складного планування та навігації. На відміну від попередніх тестів, тут використовуються спрямовані ациклічні графи, що значно ускладнює виконання завдань. Найкращі моделі показують лише 37,2% точності, що свідчить про потребу вдосконалення методів навчання з підкріпленням. Цей інструмент відкриває нові горизонти для досліджень і розвитку RL-агентів.
-
LLM потребують механізмів емпатії
дослідити →
У квітні 2026 року було опубліковано дослідження, яке вказує на системні проблеми великих мовних моделей (LLM) з емпатією — вони спотворюють емоційний та контекстуальний зміст, незважаючи на високі оцінки за стандартними тестами. Вчені виділили чотири типові помилки: послаблення почуттів, невідповідність деталізації, уникнення конфліктів і мовне дистанціювання, що ускладнює адекватне відтворення людських перспектив. Автори закликають впроваджувати в навчання LLM спеціальні емпатійні метрики та сигнали, щоб покращити їхню здатність до людяного спілкування. Наступним кроком стане розробка нових емпатійних бенчмарків і тренувальних алгоритмів.
-
LLM помилково викликають непотрібні інструменти
 дослідити →
дослідити →Дослідження виявило поширену помилку у великих мовних моделях (LLM) — структурне зміщення вирівнювання, через яке моделі викликають інструменти, що не відповідають запиту користувача. Новий набір даних SABEval допомагає розділити структурне співпадіння та семантичну релевантність, показуючи, що ця проблема залишається поза увагою існуючих оцінок. Розуміння цього зсуву допоможе підвищити точність і надійність ШІ, зменшуючи зайві виклики інструментів. Надалі дослідники планують удосконалити баланс між семантикою і структурою у прийнятті рішень.
-
PepBenchmark: новий стандарт ШІ для пептидів
дослідити →
PepBenchmark створено як перший уніфікований бенчмарк для машинного навчання пептидів, що усуває проблему відсутності стандартизації у розробці ліків. Він об’єднує 35 наборів даних, стандартизований конвеєр обробки та рейтинг моделей, охоплюючи ключові аспекти пептидної терапії. Це відкриває шлях до швидшого впровадження інновацій у фармацевтиці та медичних дослідженнях.
-
Audio-Omni: єдина модель для аудіо
 дослідити →
дослідити →Представлено Audio-Omni — першу універсальну систему, що поєднує генерацію, редагування та розуміння аудіо у сферах звуку, музики та мовлення. Архітектура поєднує заморожену мультимодальну мовну модель із тренованим дифузійним трансформером, а масштабний датасет AudioEdit з понад мільйоном пар редагувань вирішує проблему нестачі даних. Ця розробка перевершує спеціалізовані моделі і встановлює новий стандарт у сфері аудіо штучного інтелекту. Наступний крок — впровадження Audio-Omni у практичні застосунки та творчі процеси.
-
LLM-ознаки не завжди покращують RL-трейдинг
дослідити →
Нове дослідження показало, що великі мовні моделі (LLM) можуть генерувати прогностичні ознаки для агентів з підкріплювальним навчанням (RL) у трейдингу, проте під час макроекономічних шоків ці ознаки можуть погіршувати роботу агентів. Використання оптимізації підказок дозволило отримати значущі кореляції (IC понад 0,15), але в умовах змін розподілу агент із LLM-ознаками поступався базовому агенту, який працює лише з цінами. Це підкреслює важливість стійкості політик RL у нестабільних ринкових умовах. Наступним кроком стане розробка методів підвищення надійності таких систем.
-
CodaRAG: Революція в асоціативному мисленні ШІ
дослідити →
Нова технологія CodaRAG, натхненна Комплементарними системами навчання, змінює підхід до Retrieval-Augmented Generation, об’єднуючи розрізнені дані в логічні ланцюжки. На відміну від традиційних методів, які розглядають докази окремо, CodaRAG активно досліджує асоціативні зв’язки, що дозволяє підвищити точність пошуку на 7-10% та якість генерації на 3-11%. Це відкриває нові можливості для надійного та глибокого аналізу інформації в великих мовних моделях. Наступним кроком стане інтеграція CodaRAG з існуючими системами і розширення сфер застосування.
-
Новий метод без тренування виявляє витоки в LLM
дослідити →
Девід Іліч та співавтори розробили EZ-MIA — потужну атаку на автогресивні мовні моделі, що не потребує додаткового навчання. Вона виявляє випадки, коли модель помилково підвищує ймовірність токенів із тренувальних даних, що свідчить про запам’ятовування конфіденційної інформації. Це значно покращує точність виявлення при низькому рівні хибних спрацьовувань, що критично для аудиту приватності. З поширенням великих мовних моделей EZ-MIA підкреслює нагальність посилення захисту даних у майбутньому.
-
Глибинне навчання змінює прийняття рішень
 дослідити →
дослідити →Дослідження І. Есри Буюктахакин демонструє, як глибинне навчання доповнює традиційні методи оптимізації у прийнятті послідовних рішень в умовах невизначеності. Цей підхід відкриває нові горизонти для застосування штучного інтелекту у складних, динамічних системах. Важливо, що AI переходить від прогнозування до підтримки реальних рішень. Наступним кроком стане впровадження цих моделей у масштабних практичних проєктах.
-
Прогнозне кодування мозку відтворює мову
 дослідити →
дослідити →Дослідження Конгчі Іня та колег показало, що за допомогою прогнозного кодування мозку можна відтворювати мову з даних fMRI, базуючись на здатності мозку передбачати майбутні слова. Це відкриття поглиблює розуміння нейронних механізмів семантичної обробки та відкриває нові можливості для інтерфейсів мозок-комп’ютер. Наступний крок — впровадження моделей у реальному часі.
-
Покращення безпеки LLM під час інференсу
дослідити →
Дослідження Панкаяраджа Патманатхана та співавторів показало, що метод деліберативного вирівнювання, який передає навички мислення від потужніших моделей до менших, суттєво підвищує безпеку великих мовних моделей. Проте між «вчителем» і «учнем» існує розрив у вирівнюванні, що впливає на безпеку та корисність моделей. Це свідчить про необхідність подальших досліджень для забезпечення надійної роботи ШІ в реальному часі.
-
Приховані упередження омнімодальних моделей ШІ
 дослідити →
дослідити →Нове дослідження виявило суттєві демографічні та мовні упередження в омнімодальних мовних моделях, що працюють із текстом, зображеннями, аудіо та відео. Якщо завдання з обробки зображень і відео показують відносно рівномірні результати, то аудіозавдання мають значні розбіжності у точності залежно від віку, статі та мови. Це підкреслює необхідність комплексної оцінки справедливості моделей, адже їхнє застосування швидко зростає. Фахівці наголошують, що без усунення цих упереджень ШІ може посилити соціальну нерівність.
-
CheeseBench: ІІ тестують на завданнях гризунів
дослідити →
Новий бенчмарк CheeseBench оцінює великі мовні моделі за дев’ятьма класичними поведінковими нейронауковими завданнями, що базуються на досвіді з гризунами. Найкраща модель Qwen2.5-VL-7B досягла успішності у 52,6%, перевищуючи випадковий рівень, але поступаючись біологічним показникам — 78,9%. Це важливий крок у наближенні штучного інтелекту до природного пізнання. Наступний етап — вдосконалення моделей і розширення тестування.
-
ACE-TA змінює підхід до навчання кодуванню
дослідити →
ACE-TA — агентний навчальний асистент, що автономно відповідає на запитання, створює тести та проводить покрокове навчання програмуванню за допомогою великих мовних моделей. Ця система поєднує точні відповіді, адаптивні перевірки знань і інтерактивне наставництво, що суттєво покращує якість навчання. Запуск ACE-TA відкриває нові горизонти для персоналізованої та ефективної освіти. Наступний крок — широке впровадження та тестування у навчальних закладах.
-
Етика ІІ у кодуванні: що повинен знати розробник
 дослідити →
дослідити →ІІ-агенти для написання коду вже не експеримент, а невід’ємна частина робочих процесів у багатьох компаніях. Проте етичні норми відстають, залишаючи відкритими питання власності на код, упередженості, безпеки та визнання авторства. Ці проблеми не гіпотетичні — вони проявляються у вигляді прихованих помилок, вразливостей і суперечок щодо заслуг. Розробникам потрібні чіткі рамки для відповідального використання ІІ у створенні програмного забезпечення.